
Sora的展示,毫無疑問是吊打此前的runway和pikalabs的。
第六,Sora模型已經可以簡單地模擬世界狀態的動作。比如說,畫家在畫布上留下新的筆觸,這些筆觸會隨著時間的推移而持續存在,或者一個人吃漢堡的時候會留下漢堡上的咬痕。有比較樂觀的解讀認為,這意味著模型具備了一定的通識能力、能“理解”運動中的物理世界,也能夠預測到畫面的下一步會發生什么。
接下來,我們就來試圖回顧一下生成式AI大模型的技術發展之路,以及試圖解析一下,Sora的模型是怎么運作的,它到底是不是所謂的“世界模型”?
擴散模型技術路線:GoogleImagen,Runway,PikaLabs?
什么是擴散模型?張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
2)擴散過程(也被稱為前向過程forwardprocess):擴散過程的目標是讓圖片變得不清晰,最后變成完全的噪聲。
3)反向過程(reverseprocess,又被稱為backwarddiffusion):這時候我們會引入“神經網絡”,比如說基于卷積神經網絡(CNN)的UNet結構,在每個時間步預測“要達到現在這一幀模糊的圖像,所添加的噪聲”,從而通過去除這種噪聲來生成下一幀圖像,以此來形成圖像的逼真內容。
以上是videotovideo或者是picturetovideo的生成方式,也是runwayGen1的大概底層技術運行方式。如果是要達到輸入提示詞來達到texttovideo,那么就要多加幾個步驟。
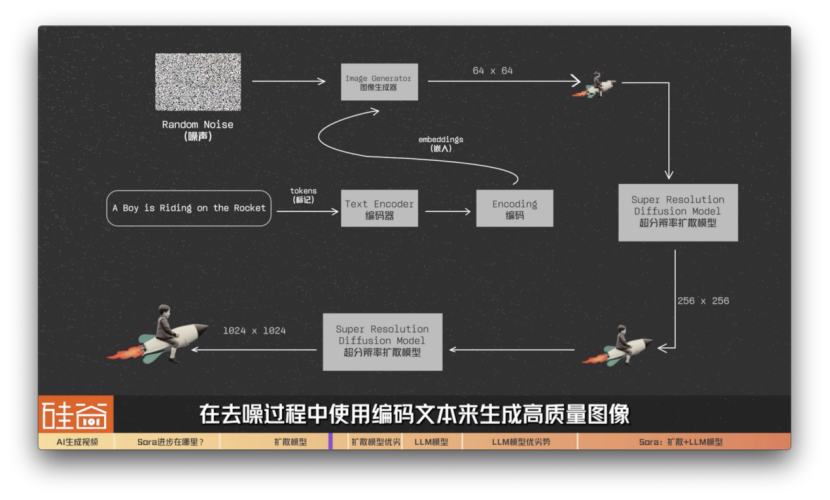
比如說我們拿谷歌在2022年中旬發布的Imagen模型來舉例:我們的提示詞是aboyisridingontheRocket,騎著火箭的男孩。這段提示詞會被轉換為tokens(標記)并傳遞給編碼器textencoder。谷歌IMAGEN模型接著用T5-XXLLLM編碼器將輸入文本編碼為嵌入(embeddings)。這些嵌入代表著我們的文本提示詞,但是以機器可以理解的方式進行編碼。
之后這些“嵌入文本”會被傳遞給一個圖像生成器imagegenerator,這個圖像生成器會生成64x64分辨率的低分辨率圖像。之后,IMAGEN模型利用超分辨率擴散模型,將圖像從64x64升級到256x256,然后再加一層超分辨率擴散模型,最后生成與我們的文本提示緊密結合的1024x1024高質量圖像。
簡單總結來說,在這個過程中,擴散模型從隨機噪聲圖像開始,在去噪過程中使用編碼文本來生成高質量圖像。
擴散模型優劣勢張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
擴散模型比起之前的GAN等模型來說,有三個主要的優點:
第一,穩定性:訓練過程通常更加穩定,不容易陷入模式崩潰或模式塌陷等問題。
第三,無需特定架構:擴散模型不依賴于特定的網絡結構,兼容性好,很多不同類型的神經網絡都可以拿來用。
然而,擴散模型也有兩大主要缺點,包括:
首先,訓練成本高:與一些其他生成模型相比,擴散模型的訓練可能會比較昂貴,因為它需要在不同噪聲程度的情況下學習去燥,需要訓練的時間更久。
張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
簡單來說,基于大語言模型的Videopoet是這樣運作的:
先來說說優點:
再來說說缺點:
張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
Transformer模型的另外一些問題還包括:
不過說到第五點,我突然想起來最近的這么一個新聞,說谷歌的多模態大模型Gemini中,無論你輸入什么人,出來的都是有色人種,包括美國開國元勛,黑人女性版本的教皇,維京人也是有色人種,生成的ElonMusk也是黑人。
這背后的原因可能是谷歌為了更正Transformer架構中的偏見,給加入了AI道德和安全方面的調整指令,結果調過頭了,出了這個大烏龍。不過這個事情發生在OpenAI發布了Sora之后,確實又讓谷歌被群嘲了一番。
不過,業內人士也指出,以上的這五點問題也不是transformer架構所獨有的,目前何生成模型都可能存在這些問題,只是不同模型在不同方向的優劣勢稍有不同。
Sora的擴散+大語言模型:1+12?但我們先從Sora公開的這篇技術解析,來看看OpenAI的擴散+大語言模型技術路線是如何操作的。
所以,Sora模型的生成的步驟包括:
第二步:文本理解
第三步:DiffusionTransformer成像
Sora采用了Diffusion和Transformer結合的方式。
目前外界有一些觀點猜測,在我們之前說到的擴散模型的第三步驟中,Sora選擇將U-Net架構替換成了Transformer架構。這讓Diffusion擴散模型作為一個畫師開始逆擴散、畫畫的時候,在消除噪音的過程中,能根據關鍵詞特征值對應的可能性概率,在OpenAI海量的數據庫中,找到更貼切的部分,來進行下筆。
我在采訪另一位AI從業者的時候,他用了另外一個生動的例子解釋這里的區別。他說:“擴散模型預測的是噪音,從某個時間點的畫面,減去預測的噪音,得到的就是最原始沒有噪音的畫面,也就是最終生成的畫面。這里更像是雕塑,就像米開朗基羅說的,他只是遵照上帝的旨意將石料上不應該存在的部分去掉,最終他才從中創造出偉大的雕塑作品。而Transformer通過自注意力機制,理解時間線之間的關聯,讓這尊雕塑從石座上走了下來。”是不是還挺形象的?
說實話,Transformer加擴散模型的方法論并不是OpenAI獨創的,在OpenAI發布Sora之前,我們在和張宋揚博士今年一月份采訪的時候,他就已經提到說,Transformer加擴散模型的方式已經在行業中開始普遍的被研究了。
張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
所以,這也解釋了為什么OpenAI現在要發布Sora,其實在OpenAI的論壇上,Sora方澄清說,Sora現在并不是一個成熟的產品,所以,它不是已發布的產品,也不公開,沒有等候名單,也沒有預計的發布日期。
張宋揚博士,MetaMake-A-Video模型的論文作者之一、亞馬遜AGI團隊應用科學家:
以上是我們對Sora非常初步的分析,再次說明一下,因為Sora非常多技術細節沒有公開,所以我們的很多分析也是從外部視角去做的一個猜測,如果有不準確的地方,歡迎大家來糾錯,指正和探討。
免責聲明:本文章如果文章侵權,請聯系我們處理,本站僅提供信息存儲空間服務如因作品內容、版權和其他問題請于本站聯系